I Tried OpenRouter Fusion So You Don’t Have To (But You’ll Want To Anyway)
I Tried OpenRouter Fusion So You Don’t Have To (But You’ll Want To Anyway)
If you’ve ever opened four different AI chats to answer one hard question and then played “LLM referee” in your head, you’re going to like this.
OpenRouter just shipped something called Fusion, and it basically turns that chaotic “ask five models, squint at the answers, and pray” workflow into a single API call with a built‑in judge model.
As someone who lives in the land of deep research, valuation models, and AI agent orchestration, this is the first time I’ve looked at an LLM product and thought, “Oh, this is compound AI for grown‑ups.”
What Fusion Actually Does
At a high level, Fusion takes your prompt and:
Fans it out to a panel of models in parallel (GPTs, Anthropic, Gemini, strong open models, etc.).
Let’s each of them use tools like web search and web fetch to go hunting for evidence.
Hands all those responses to a judge model that doesn’t just mash them together, it analyzes them.
The judge pulls out consensus points, contradictions, partial coverage, unique insights, and blind spots, then uses that structure to write the final answer.
From your side, it feels like… nothing special. Just send a request with model: "openrouter/fusion" and you get one response back. Under the hood, you’ve just run a small AI panel discussion.
Why Deep Research Needs This
Deep research is where single‑model heroics start to break down:
You need multiple perspectives: legal, financial, technical, product, user.
You need tool use: search, retrieval, maybe even bash or code execution.
You need consistency and grounding, not just pretty paragraphs.
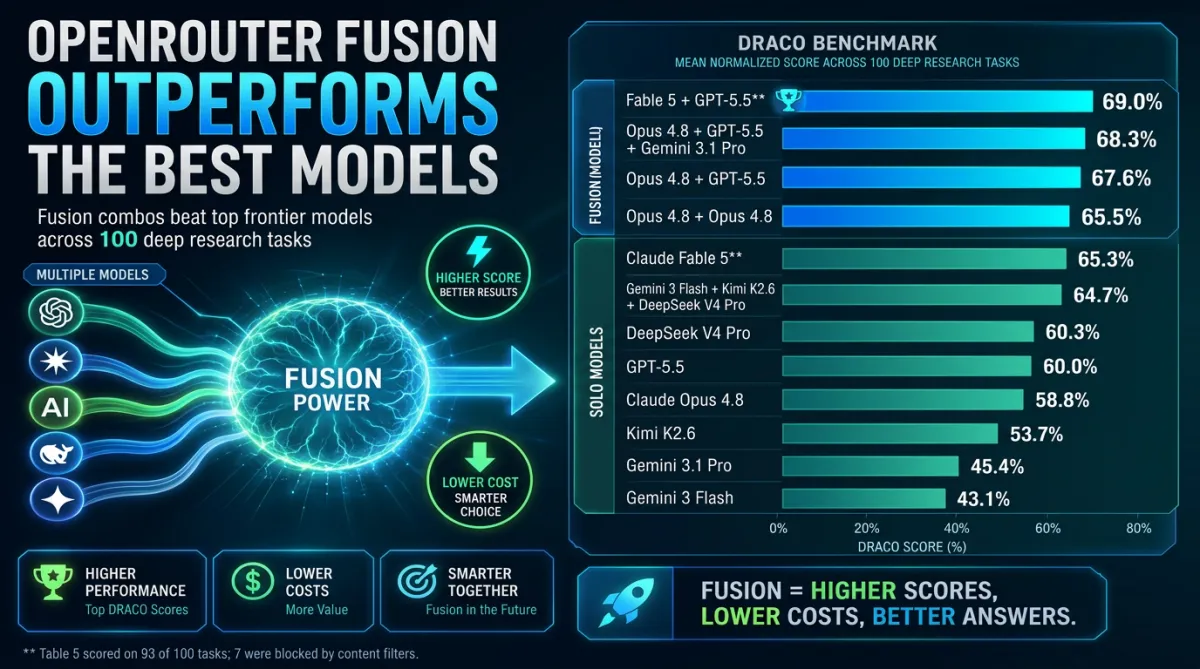
OpenRouter tested Fusion on DRACO, Perplexity’s deep research benchmark: 100 hard tasks across law, medicine, finance, technology, product comparison, and more.
The punchline from their reported numbers:
A panel of Fable 5 + GPT‑5.5, fused by a strong judge, scored around 69%.
Solo Fable 5 landed closer to 65.3%.
Across runs, panels consistently beat single models, including frontier models.
So, the claim is basically: Fable‑level deep research performance at roughly half the cost, if you’re willing to let a panel of cheaper or mixed models do the heavy lifting.
As an architect, that unlocks a very nice design space:
Use budget models for breadth and exploration.
Use a smart judge to enforce quality.
Keep the whole thing behind a single interface your app already understands.
The Counterintuitive Bit: Even Fusing One Model Helps
One of my favorite details from the Fusion test results: even fusing a model with itself works.
Example: run Opus 4.8 twice, take both reasoning paths, and have the judge synthesize. That setup reportedly jumped from around 58.8% solo to 65.5% fused—without model diversity.
That tells you something important:
The synthesis step is not a gimmick.
Different tool calls, different sources, different chains of reasoning—even with the same base model—can be combined into something better than any one run.
If you’re already running multiple “just to be safe” calls in your own stack, Fusion basically productizes that pattern.
How Fusion Fits Into a Real Stack
From a CTO / architect lens, here’s how I’d think about slotting Fusion into an existing AI setup:
1. As the “Deep Research Mode” Switch
Keep your normal fast model (Gemini Flash, GPT‑x Mini, etc.) for:
Short Q&A
UI helpers
Simple automations
Then route high‑stakes, high‑complexity questions to Fusion instead:
Investment memos, legal pre‑reads, product landscape comparisons
Multi‑source synthesis (documents + web + internal knowledge)
Anything where “oops” is expensive
Fusion’s default routing runs a panel of 1–8 models plus a judge, with tools enabled, behind that one slug.
2. As a Configurable “Compound Model” Primitive
OpenRouter exposes Fusion as:
A model alias: openrouter/fusion (just use it like any other model).
A server tool (openrouter:fusion), so your base model can decide when to invoke a panel.
A browser/chat interface, where you can configure a custom panel without writing code.
That means you can:
Start with the default panel for simplicity.
Graduate to a custom “Colin panel”: maybe Gemini Flash + DeepSeek V4 Pro + one weirdly good open model, with a strong Anthropic judge on top.
Cost: Why This Isn’t Just a Science Project
One of the big claims from OpenRouter’s own numbers: budget panels can beat single frontier models at about half the price.
For example:
A panel of Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro reportedly beat solo GPT‑5.5 and solo Opus 4.8 on DRACO, while landing within about 1% of Fable 5.
Cost came in at roughly 50% of a frontier‑model‑only setup for the same benchmark tasks.
If you’re running lots of deep research calls—say, in a research SaaS, RFP assistant, or internal strategy copilot—that cost delta is not academic. It’s the difference between “cool demo” and “we can afford to leave this on by default.”
Developer Experience: How You Actually Use It
From a dev point of view, the nice part is: there’s nothing exotic here.
API: Use the standard OpenAI‑compatible chat completions endpoint, set model to "openrouter/fusion" and send your usual messages array.
Tools: Models in the panel can call openrouter:web_search and openrouter:web_fetch, and in some setups even bash‑like tooling, so they can do real retrieval instead of hallucinating citations.
Config: Through docs and the UI, you can tweak which participant models are in the panel, how many to run, and which model acts as the judge/synthesizer.
If you’ve already wired apps to OpenRouter (or any OpenAI‑style endpoint), Fusion is more of a routing decision than a whole new integration.
Where I’d Use Fusion First
If I were rolling this into client projects or my own tools, here are the first places I’d test it:
Valuation and deal memos
Let a panel battle it out on comps, narratives, risks, and scenario framing, instead of trusting one model’s first draft.Competitive landscapes & product comparisons
Fusion is built for “what’s actually different here?” and “who’s saying what in the wild?” style questions.Policy, legal, and compliance pre‑research
Not as a lawyer replacement, but as a better “first pass” before a human review, especially when you want to see conflicting interpretations surfaced, not hidden.Knowledge‑heavy agent chains
Use Fusion as the “oracle step” for especially gnarly hops in a multi‑agent workflow, instead of chaining 12 calls to one model that might drift.
So… Should You Care?
If your stack mostly does simple chatbots, you may not need Fusion right away. A single high‑end model is already overkill for FAQ‑style tasks.
But if you:
Live in deep research,
Care about source‑grounded reasoning,
And you’re tired of playing manual “which model do I trust?” every day,
then Fusion is absolutely worth experimenting with. It’s one of the first mainstream products that treats multi‑model, judge‑style synthesis as a first‑class primitive instead of a DIY hack on top of five different APIs.
And the best part for builders like us: from the outside, it still looks like “just another model.” That’s exactly the kind of complexity I like—hidden behind a clean interface, where I can flip it on in one place and watch the rest of the system quietly get smarter.
